Data Engineer Tool Selection
Combination of Reading O'Reilly Books, working with Google Gemini Pro and my own thinking about business and data system concerns at tool selection.
January 2026
01
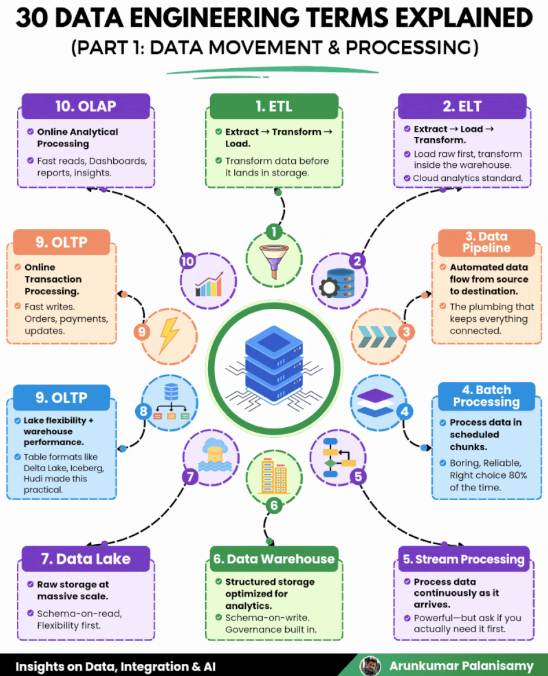
Data Latency: How fast do you need it?
- Sub-second / Real-time: You need a stream processor.
- Tooling: Apache Flink, Spark Streaming, or Confluent (Kafka).
- Minutes to Hours (Micro-batch/Batch): Standard ETL/ELT is fine.
- Tooling: dbt, Apache Airflow, or Dagster.
02
Data Volume & Complexity
- Small to Medium (< 1TB, Structured): Don't over-engineer. Use a cloud warehouse.
- Tooling: Snowflake, BigQuery, or PostgreSQL (if very small).
- Massive / Unstructured (> 10TB, Logs, JSON, Images): You need a Data Lakehouse.
- Tooling: Databricks (Spark), Starburst (Trino), or AWS Athena.
03
Storage Format (The Lakehouse Strategy)
If you went the Lakehouse route, you must pick a table format to handle ACID transactions on files:
- Heavy Upserts/Deletes: Apache Hudi.
- High Performance / Ecosystem Support: Apache Iceberg (The current industry favorite for interoperability).
- Deep Databricks Integration: Delta Lake.
04
Transformation Logic
- SQL-heavy / Analyst Friendly: dbt is the gold standard for modular SQL.
- Complex Python / ML Logic: Apache Spark or Ray.
01
Cross Check before Takoff
Before finalizing a tool, ask yourself these three non-technical questions:
Total Cost of Ownership (TCO):
Is the licensing + engineering hours to maintain it cheaper than a managed service?
02
Team Skillset:
Does my team know Scala/Java, or are they strictly SQL/Python? (Don't buy a Ferrari if no one can drive manual).
03
Vendor Lock-in:
How hard is it to migrate our metadata if this vendor hikes prices by 30% next year?